| Information | Metadata Extractors |
|---|---|
| Support Status | Full Support |
| Architecture Information | Platform Architecture |
| Description | Every time a file is uploaded to the repository the file's MIME type is
automatically detected. Based on the MIME type a related Metadata Extractor is
invoked on the file. It will extract common properties from the file, such as
author, and set the corresponding content model property accordingly. Each
Metadata Extractor has a mapping between the properties it can extract and the
content model properties. Metadata extraction is primarily based on the Apache
Tika library. This means that whatever file formats Tika can extract metadata from, SkyVault Community Edition can also
handle. To give you an idea of what file formats SkyVault Community Edition can extract
metadata from, here is a list of the most common formats:
The properties that are extracted are limited to the out-of-the-box content model, which is very generic. Here are some example of extracted property name and what content model property it maps to:
One thing to note though, event if an extractor can extract any of the system controlled properties, such as created date, it will not be used. Created date, creator, modified date, and modifier is always controlled by the SkyVault Community Edition system, unless you are using the Bulk Import tool, in which case last modified date can be preserved. A common requirement is to be able to change the mapping of out-of-the-box properties, such as having the subject property mapped to cm:title instead of cm:description. This is quite easy to achieve, just override the out-of-the-box bean and re-configure the mapping. The out-of-the-box Spring bean definitions for Metadata Extractors can be found in the content-services-context.xml file, which is located here. Search for "Content Metadata Extractors" in the file and then you will find an ordered list of extractor definitions. When overriding a Metadata Extractor configuration you have the option to inherit the default properties mapping or define a new one from scratch. For example, to change the subject property so it is mapped to content model property cm:title for PDF files re-define the extracter.PDFBox Spring bean as follows: <bean id="extracter.PDFBox" class="org.alfresco.repo.content.metadata.PdfBoxMetadataExtracter"
parent="baseMetadataExtracter">
<property name="documentSelector" ref="pdfBoxEmbededDocumentSelector" />
<property name="inheritDefaultMapping">
<value>false</value>
</property>
<property name="mappingProperties">
<props>
<prop key="namespace.prefix.cm">http://www.alfresco.org/model/content/1.0</prop>
<prop key="author">cm:author</prop>
<prop key="subject">cm:title</prop>
<prop key="Keywords">cm:description</prop>
</props>
</property>
</bean>
In this case you also map the author property. This is
because when you set the inheritDefaultMapping property to
false all the default property mappings are not used.
Another property called Keywords have also been mapped to
the cm:description property. Note that all the namespaces
that the content model properties belong to have to be specified as in the
above example with namespace.prefix.cm. It is also very
important to know that the property names are case sensitive. So if the
Keyword property had been written with a lower-case k, it
would not have been picked up. Sometimes it can be useful to know what
metadata extractor that is actually used when you upload a document. Turning
on Metadata Extractionb logging is a good idea to get on top of what is
happening. Set the following property in log4j.properties:
log4j.logger.org.alfresco.repo.content.metadata=DEBUGWith logging turned on the following information will be logged when uploading a PDF: 2015-12-07 13:56:51,324 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Get extractors for application/pdf 2015-12-07 13:56:51,324 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Finding extractors for application/pdf 2015-12-07 13:56:51,326 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find supported: extracter.TikaAuto 2015-12-07 13:56:51,326 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find supported: extracter.PDFBox 2015-12-07 13:56:51,326 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.Poi 2015-12-07 13:56:51,326 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.Office 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.Mail 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.Html 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.OpenDocument 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.DWG 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.RFC822 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.MP3 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.Audio 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: extracter.OpenOffice 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find unsupported: org.alfresco.tutorial.metadataextracter.xml.AcmeDocXMLMetadataExtracter 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Find returning: [org.alfresco.repo.content.metadata.TikaAutoMetadataExtracter@763b7315, org.alfresco.repo.content.metadata.PdfBoxMetadataExtracter@6acadc76] 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Get supported: extracter.TikaAuto 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Get supported: extracter.PDFBox 2015-12-07 13:56:51,327 DEBUG [content.metadata.MetadataExtracterRegistry] [http-bio-8080-exec-14] Get returning: extracter.PDFBox You can clearly see that the PDFBox extractor is invoked so you know you have
customized the correct one. What about the properties? It is likely that you
will struggle to figure out what properties are extracted and their names.
You can have this logged with the following log file configuration:
log4j.logger.org.alfresco.repo.content.metadata.AbstractMappingMetadataExtracter=DEBUGThis log configuration is set to some other log level out-of-the-box so you need to specifically re-configure it to be able to see something. Now when running you will also see the extracted doc properties as in the following example: Found: {
pdf:PDFVersion=1.4,
xmp:CreatorTool=Writer,
Keywords=SomeKeyword1, SomeKeyword2,
subject=SomeSubject,
dc:creator=Martin Bergljung,
description=SomeSubject,
dcterms:created=2015-12-07T14:22:15Z,
dc:format=application/pdf; version=1.4,
title=SomeTitle,
dc:title=SomeTitle,
pdf:encrypted=false,
cp:subject=SomeSubject,
Content-Type=application/pdf,
creator=Martin Bergljung,
comments=null,
meta:author=Martin Bergljung,
dc:subject=SomeKeyword1, SomeKeyword2,
meta:creation-date=2015-12-07T14:22:15Z,
created=2015-12-07T14:22:15Z,
author=Martin Bergljung,
xmpTPg:NPages=1,
Creation-Date=2015-12-07T14:22:15Z,
meta:keyword=SomeKeyword1, SomeKeyword2,
Author=Martin Bergljung, producer=LibreOffice 4.2
}
There is also a log entry with information about what properties that were actually successfully mapped: Mapped and Accepted: {
{http://www.alfresco.org/model/content/1.0}description={en_GB=SomeKeyword1, SomeKeyword2},
{http://www.alfresco.org/model/content/1.0}title={en_GB=SomeSubject},
{http://www.alfresco.org/model/content/1.0}author=Martin Bergljung}
Next requirement is most likely to map properties to custom content models. There is an ACME content model tutorial where the base document type has an acme:documentId property. You might want to add a document identifier to the PDFs you are uploading and have it automatically set in the ACME content model. Start by updating the extractor configuration as follows: <bean id="extracter.PDFBox" class="org.alfresco.repo.content.metadata.PdfBoxMetadataExtracter"
parent="baseMetadataExtracter">
<property name="documentSelector" ref="pdfBoxEmbededDocumentSelector" />
<property name="inheritDefaultMapping">
<value>false</value>
</property>
<property name="mappingProperties">
<props>
<prop key="namespace.prefix.cm">http://www.alfresco.org/model/content/1.0</prop>
<prop key="namespace.prefix.acme">http://www.acme.org/model/content/1.0</prop>
<prop key="author">cm:author</prop>
<prop key="subject">cm:title</prop>
<prop key="Keywords">cm:description</prop>
<prop key="DocumentId">acme:documentId</prop>
</props>
</property>
</bean>
Here the custom document property DocumentId has been added so it is mapped to the ACME content model property acme:documentId. When doing this you also need to define the new custom namespace acme. For this to work you need to have a rule on the folder that applies the acme:document type to any PDF document uploaded to the folder. This type has the acme:docuementId property. Now, what if you would like to extract metadata from an XML file, how would you go about that? This can be achieved with the XmlMetadataExtracter, which in-turn uses the XPathMetadataExtracter to navigate the XML and extract metadata. Let's say we had XML files looking like this: <?xml version="1.0" encoding="UTF-8"?>
<doc id="doc001">
<project>
<number>PX001</number>
</project>
<securityClassification>Company Confidential</securityClassification>
<text>
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Praesent tincidunt luctus ante, in pulvinar ante rutrum
quis. Etiam maximus arcu ut metus sollicitudin laoreet. Pellentesque ac purus nec massa euismod iaculis a sed
sapien. Integer id nisi eu tellus commodo congue. In bibendum dapibus porttitor. Aenean lobortis sodales risus
....
</text>
</doc>
And whenever we upload one we want to have the /doc/@id
attribute set as acme:documentId,
/doc/project/number set as
acme:projectNumber, and
/doc/securityClassification set as
acme:securityClassification. This will require
configuration like this, note these are new bean definitions, no overrides
as in previous examples: <bean id="org.alfresco.tutorial.metadataextracter.xml.AcmeDocXPathMetadataExtracter"
class="org.alfresco.repo.content.metadata.xml.XPathMetadataExtracter"
parent="baseMetadataExtracter"
init-method="init">
<property name="mappingProperties">
<bean class="org.springframework.beans.factory.config.PropertiesFactoryBean">
<property name="location">
<value>
classpath:alfresco/module/${project.artifactId}/metadataextraction/acme-content-model-mappings.properties
</value>
</property>
</bean>
</property>
<property name="xpathMappingProperties">
<bean class="org.springframework.beans.factory.config.PropertiesFactoryBean">
<property name="location">
<value>
classpath:alfresco/module/${project.artifactId}/metadataextraction/acme-xml-doc-xpath-mappings.properties
</value>
</property>
</bean>
</property>
</bean>
<bean id="org.alfresco.tutorial.metadataextracter.xml.selector.AcmeDocXPathSelector"
class="org.alfresco.repo.content.selector.XPathContentWorkerSelector"
init-method="init">
<property name="workers">
<map>
<entry key="/*">
<ref bean="org.alfresco.tutorial.metadataextracter.xml.AcmeDocXPathMetadataExtracter"/>
</entry>
</map>
</property>
</bean>
<bean id="org.alfresco.tutorial.metadataextracter.xml.AcmeDocXMLMetadataExtracter"
class="org.alfresco.repo.content.metadata.xml.XmlMetadataExtracter"
parent="baseMetadataExtracter">
<property name="overwritePolicy">
<value>EAGER</value> <!-- Put the extracted metadata into the content model property as long as it is not null -->
</property>
<property name="selectors">
<list>
<ref bean="org.alfresco.tutorial.metadataextracter.xml.selector.AcmeDocXPathSelector"/>
</list>
</property>
</bean>
The acme-content-model-mappings.properties file contains mappings from the extracted XML doc properties to the content model properties: # Namespaces namespace.prefix.acme=http://www.acme.org/model/content/1.0 # Mappings - metadata property -> content model property documentId=acme:documentId securityClassification=acme:securityClassification projectNumber=acme:projectNumber The property mapping can always be done in .properties files if we like, and we could have used a .properties file for the PDFBoxMetadataExtracter too. The other properties file called acme-xml-doc-xpath-mappings.properties contains the XPath expression configuration for where to find the metadata in the XML file: # XPath Mappings - metadata property -> XML Document XPATH documentId=/doc/@id securityClassification=/doc/securityClassification projectNumber=/doc/project/number |
| Metadata extractor limits |
Metadata extraction limits allows configurations on
AbstractMappingMetadataExtracter for:
The default values for each of these properties are MAX value specified in the java code. These limits are configured per extractor and mimetype. The limits configured for SkyVault Community Edition
are:
Time out configured for all extractor and all mimetypes content.metadataExtracter.default.timeoutMs=20000 Maximum size of a document to process - configured for PdfBoxMetadataExtracter , pdf files content.metadataExtracter.pdf.maxDocumentSizeMB=10 Maximum number of concurrent extractions - configured for PdfBoxMetadataExtracter , pdf files content.metadataExtracter.pdf.maxConcurrentExtractionsCount=5 |
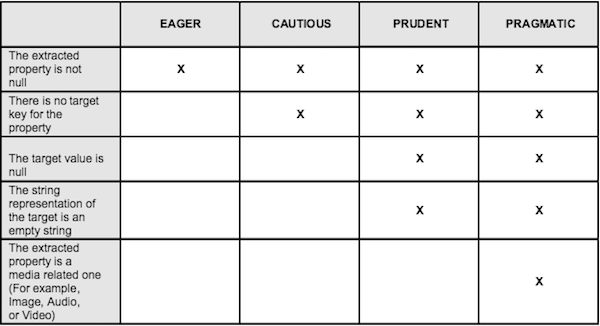
| PDF metadata extractor overwrite policy |
There are four types of overwrite policies that can be used when extracting
metadata:
The following table shows which conditions must be met for overwriting the value:
The default overwrite policy is PRAGMATIC. To change the overwrite policy,
set the overwritePolicy property. For
example:
<property name="overwritePolicy"> <value>EAGER</value> </property> To change the overwrite policy for the PDF metadata extractor, set the
overwritePolicy property in the
SkyVault-global.properties. For
example:
content.metadataExtracter.pdf.overwritePolicy=EAGER |
| Deployment - App Server |
|
| Deployment - SDK Project |
|
| More Information | |
| Sample Code | |
| Tutorials | |
| Developer Blogs |
|
You are here
Metadata Extractors
SkyVault Community Edition performs metadata
extraction on content automatically, however, you may wish to create custom metadata
extractors to handle custom file properties and custom content models.
© 2017 TBS-LLC. All Rights Reserved. Follow @twitter