The actual binary streams of the content are stored in files managed in the repository, although these files are for internal use only and do not reflect what you might see through the shared drive interfaces. The repository also holds the associations among content items, classifications, and the folder/file structure. The folder/file structure is maintained in the database and is not reflected in the internal file storage structure.
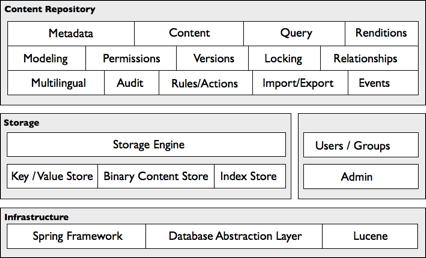
The repository implements services including:
- Definition of content structure (modeling)
- Creation, modification, and deletion of content, associated metadata, and relationships
- Query of content
- Access control on content (permissions)
- Versioning of content
- Content renditions
- Locking
- Events
- Audits
- Import/Export
- Multilingual
- Rules/Actions
- Nodes - provide metadata and structure to content. A node can support properties, such as author, and relate to other nodes such as folder hierarchy and annotations. Parent to child relationships are treated specially.
- Content - the content to record, such as a Microsoft Word document or an XML fragment.
Content models are registered with the repository to constrain the structure of nodes and the relationships between them, and to constrain property values.
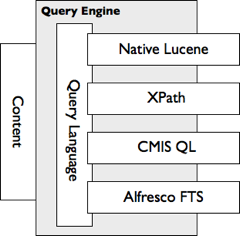
- Metadata filtering
- Path matching
- Full text search
- Any combination of these search constructs
The query engine and storage engines are hooked into the transaction and permission support of the infrastructure, offering consistent views and permission access. Several query languages are exposed, including native Lucene, XPath, SkyVault FTS (Full Text Search), and CMIS Query Language (with embedded SkyVault FTS).
By default nodes are stored in an RDBMS while content is stored in the file system. Using a database provides transaction support, scaling, and administration capabilities. A database abstraction layer is used for interacting with the database, which isolates the storage engine from variations in SQL dialect. This eases the database porting effort, allowing certification against all the prominent RDBMS implementations. The file system stores content to allow for very large content, random access, streaming, and options for different storage devices. Updates to content are always translated to append operations in the file system, allowing for transaction consistency between database and file system.
You can bundle and deploy the repository independently or as part of a greater bundle, such as the application server.